Python获取腾讯视频真实地址
一、需求
当我们浏览视频网页时,有可能想要下载下来某个视频,或者想要 跳过臭长的广告(慎),但是现在的网站往往不提供直接下载mp4或其他格式的视频文件的功能。我们通过使用Python配合Chrome浏览器,可以获取到腾讯视频的视频真实地址,直接下载视频文件。
二、实现
以下以小猪佩奇某一集为例,看看如何得到视频地址。1
https://v.qq.com/x/cover/bzfkv5se8qaqel2/b0020buglwx.html
有一种思路是:使用Chrome浏览器的开发者工具,监控网页加载过程中发出的每个请求和服务器的回复,从中查找关于视频信息的蛛丝马迹。当发现可疑的request时,查看该请求发出的所有参数内容,使用Python拼装相应的参数,并构造虚假的http请求头,模拟成用户通过网页的点击,向服务器发出请求,获取服务器回复内容,然后从回复内容中解析出视频地址。
根据以前的经验,这些网站的开发者,在移动端的功能实现会相对简单一些,我们更容易识别和抓取,因此我们解析的时候使用浏览器模拟成移动端,如图:
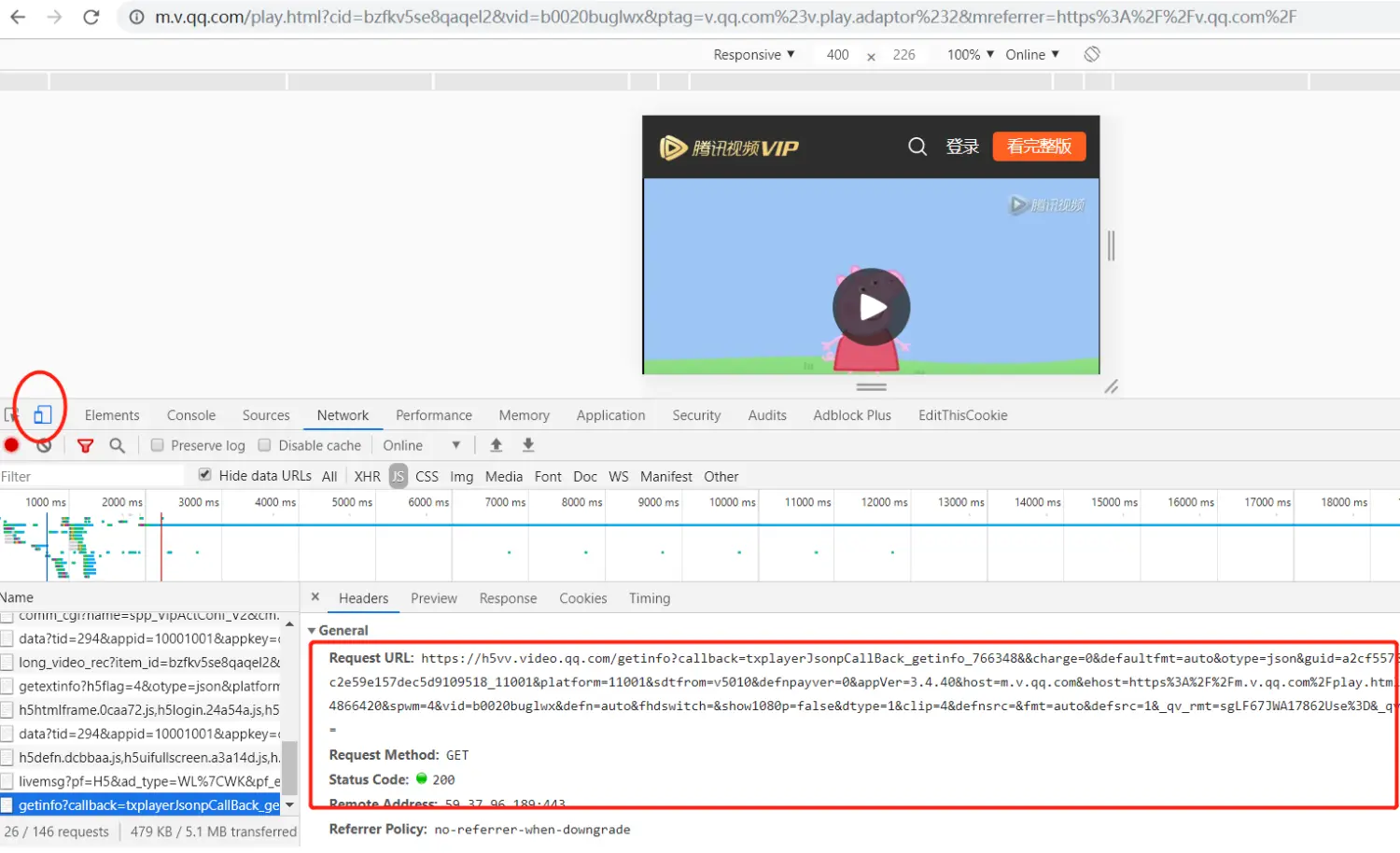
我们用Python,拼接出图中方框Request的URL地址,填入参数,发出GET请求,就可以得到一个包含视频信息的json字符串。
GET请求的URL是:1
http://h5vv.video.qq.com/getinfo?
问号后面由很多包含参数名称和值的组合构成,例如
otype=json&platform=11&defnpayver=1&appver=3.4.40
其中一个重要的参数vid,就是视频地址本身提供的:

当我们发出get请求,得到的json数据类似这样:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220{
"dltype": 1,
"exem": 0,
"fl": {
"cnt": 4,
"fi": [
{
"id": 10203,
"name": "sd",
"lmt": 0,
"sb": 1,
"cname": "标清;(270P)",
"br": 37,
"profile": 1,
"drm": 0,
"video": 1,
"audio": 1,
"fs": 5705248,
"super": 0,
"hdr10enh": 0,
"sname": "标清",
"resolution": "270P",
"sl": 0
},
{
"id": 10212,
"name": "hd",
"lmt": 0,
"sb": 1,
"cname": "高清;(480P)",
"br": 42,
"profile": 1,
"drm": 0,
"video": 1,
"audio": 1,
"fs": 10092707,
"super": 0,
"hdr10enh": 0,
"sname": "高清",
"resolution": "480P",
"sl": 0
},
{
"id": 10201,
"name": "shd",
"lmt": 0,
"sb": 1,
"cname": "超清;(720P)",
"br": 62,
"profile": 1,
"drm": 0,
"video": 1,
"audio": 1,
"fs": 19246460,
"super": 0,
"hdr10enh": 0,
"sname": "超清",
"resolution": "720P",
"sl": 1
},
{
"id": 10209,
"name": "fhd",
"lmt": 3,
"sb": 1,
"cname": "蓝光;(1080P)",
"br": 67,
"profile": 1,
"drm": 0,
"video": 1,
"audio": 1,
"fs": 40730393,
"super": 0,
"hdr10enh": 0,
"sname": "蓝光",
"resolution": "1080P",
"sl": 0
}
]
},
"fp2p": 2,
"hs": 0,
"ip": "113.110.230.111",
"ls": 0,
"preview": 299,
"s": "o",
"sfl": {
"cnt": 0
},
"tstid": 3,
"tm": 1574871391,
"vl": {
"cnt": 1,
"vi": [
{
"br": 62,
"ch": 0,
"cl": {
"fc": 1,
"ci": [
{
"idx": 1,
"cs": 19246460,
"cd": "299.96",
"cmd5": "f579ecf14d0aa58c0bc846f40ebe0c7c",
"vkey": "",
"urllist": [],
"keyid": "q0020tfo8j7.10201.1"
}
]
},
"ct": 21600,
"drm": 0,
"dsb": 0,
"fclip": 1,
"fmd5": "f579ecf14d0aa58c0bc846f40ebe0c7c",
"fn": "q0020tfo8j7.p201.mp4",
"fs": 19246460,
"fst": 5,
"fvkey": "6D7FDA1832CC88940F6F20E281EE9727639DF6B0D70FFF73083818AB45289A0507A0FD280B370536D0918C1A3564AA34F9698B83C61A88962F765BBF7EA67010F5B4D1D11737658D783A86ED5A5EA22933C2838506DEC3B16C1223E7727442E18A1AA2630567BFD436C4353F31F5A0E5",
"head": 0,
"hevc": 0,
"iflag": 0,
"level": 0,
"lnk": "q0020tfo8j7",
"logo": 1,
"mst": 8,
"pl": [
{
"cnt": 3,
"pd": [
{
"cd": 2,
"h": 45,
"w": 80,
"r": 10,
"c": 10,
"fmt": 40001,
"fn": "q1",
"url": "http: //puui.qpic.cn/video_caps/0/"
},
{
"cd": 2,
"h": 90,
"w": 160,
"r": 5,
"c": 5,
"fmt": 40002,
"fn": "q2",
"url": "http://puui.qpic.cn/video_caps/0/"
},
{
"cd": 2,
"h": 135,
"w": 240,
"r": 5,
"c": 5,
"fmt": 40003,
"fn": "q3",
"url": "http://puui.qpic.cn/video_caps/0/"
}
]
}
],
"share": 1,
"sp": 0,
"st": 2,
"tail": 0,
"td": "299.96",
"ti": "恐龙先生弄丢了",
"tie": 0,
"type": 1036,
"ul": {
"ui": [
{
"url":"http://113.105.141.22/vlive.qqvideo.tc.qq.com/AF094anUFAellJsZIYnUozoSnZLLcgP480IDBq7WleyE/uwMROfz2r5zCIaQXGdGnC2dfKb2-hlZWyQT_tzD-Vsr
eqSpl/",
"vt": 203,
"dtc": 0,
"dt": 2
},
{
"url": "http: //lmsjy.qq.com/uwMROfz2r5zCIaQXGdGnCmdfKb0i2sHXl3M2Wy9RmDZEeplY/",
"vt": 170,
"dtc": 0,
"dt": 2
},
{
"url": "http://lmbsy.qq.com/uwMROfz2r5zCIaQXGdGmm2dfKb0Pk2-yYlV7ZrIrO9TJ-LqW/",
"vt": 130,
"dtc": 0,
"dt": 2
},
{
"url": "http://video.dispatch.tc.qq.com/uwMROfz2r5zCIaQXGdGmlWdfKb2svKK_VNuAbg616jtBjIn0/",
"vt": 0,
"dtc": 0,
"dt": 2
}
]
},
"vh": 720,
"vid": "b0020buglwx",
"videotype": 106,
"vr": 0,
"vst": 2,
"vw": 1280,
"wh": 1.7777778,
"wl": {
"wi": []
},
"uptime": 1465198419,
"fvideo": 0,
"cached": 1,
"fvpint": 0,
"swhdcp": 0
}
]
}
}
看到这其中包含很多的url地址,可以确定视频地址的信息就在其中,不过还需要分析一下,怎么样根据这些数据把视频地址拼接出来。
其实浏览器也是根据这个json数据,通过调用js脚本获取到视频地址,但是如果要通过解析js脚本获取地址就会很麻烦,尤其是考虑到js脚本可能经过了压缩和加密。所以还是通过浏览器开发者工具,查看浏览器实际get请求中的数据格式,以供参考。
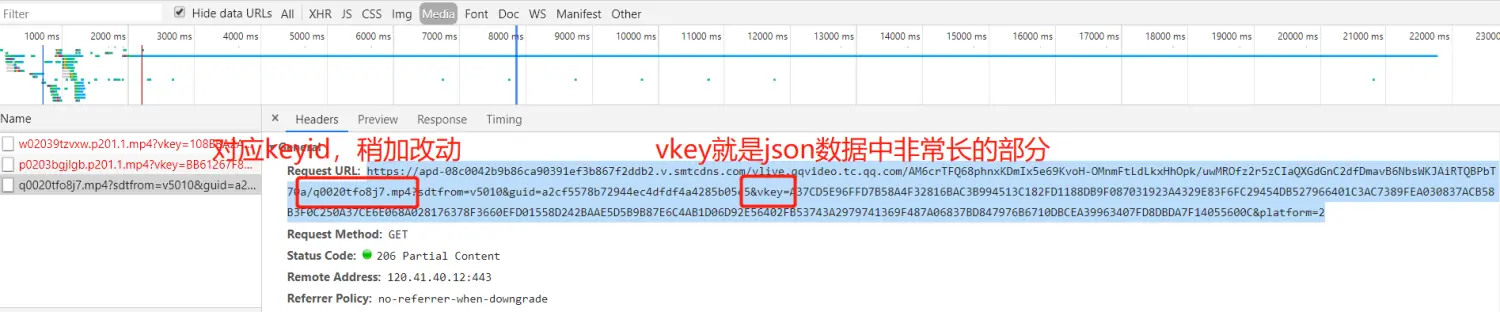
经测试其中有些参数可以不传入。最终代码如下,只需传入一个网址,就可以获取到mp4格式视频的一个url(默认就是最高清晰度)。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import requests
import re
import json
headers = {
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
def getTencentVideoUrl(url):
vid = url.split('/')[-1][:-5]
url = 'http://h5vv.video.qq.com/getinfo?otype=json&platform=11&defnpayver=1&appver=3.4.40&defn=fhd&vid=' + vid
html = requests.get(url, headers=headers).text
# 获取json数据
p = re.compile(r'({.*})', re.S)
jsonstr = re.findall(p, html)[0]
json_data = json.loads(jsonstr)
print(jsonstr)
# 解析json数据获取url
fvkey = json_data['vl']['vi'][0]['fvkey']
keyid = json_data['vl']['vi'][0]['cl']['ci'][0]['keyid'].split('.')
filename = keyid[0] + '.p' + keyid[1][2:] + '.' + keyid[2] + '.mp4'
baseUrl = json_data['vl']['vi'][0]['ul']['ui'][3]['url'] # 实际数据中有多个cdn可供选择
result = baseUrl + filename + '?vkey=' + fvkey
return result
if __name__ == '__main__':
url = input('请输入腾讯视频网址:')
print('视频下载地址:\n', getTencentVideoUrl(url))
三、问题:
实际上有些视频是分成了多个小部分,这时就会需要获取每个视频的地址,下载下来然后再拼接成一个完整的视频文件,如果想要做的话也是可以的,自动下载多段视频,然后自动合并成1个完整的文件。
这里可能就不能只发送一次get请求了,而是根据视频分割成了多少个,发送多次请求。